
A benefit of being an independent contractor is playing with a lot of cool technology. Many libraries on the market use machine learning (ML) to perform image recognition and video analysis. Knowing the basics is essential to getting the final solution working well.
One of my clients is building a service in Amazon AWS and wants to use Amazon Rekognition to find logos in videos. Amazon Rekognition has predefined classifiers that can detect pre-trained instances such as object, scene, and concept detection, text, unsafe content, celebrity recognition, facial analysis, and custom labels. The custom labels had to be chosen as no pre-trained classifier was available.
When selecting images, there are a few considerations:
- Only image files can be processed. This requires videos to be split into individual files.
- Supported image types are PNG and JPG, with a maximum image size of 4096 * 4096 pixels.
- Data is stored in a S3 bucket.
- At least 10 training and 10 test images per class must be selected.
- Training of a model takes between 0.5 hrs and 24 hrs.
While this is specific to AWS Rekognition, every library has different limitations. These could include the number of images a library supports, the file format, how many classes are allowed per classifier, or the size of images.
I trained support vector machines (SVMs) beforehand, and the recommendation was to use at least 1000 images per class. This is a lot of images, and I was surprised that AWS Rekognition didn’t want/need as many. A word of caution: it highly depends on the use case and the variation of the incoming data! More later on this topic.
The task: Detect monster logos in social media posts
A set of images containing the monster logo was provided to me. As they came from social media posts, some of these images didn’t have a high resolution. Some logos weren’t easy to see on the first look by the human eye. My hopes of getting a decent classifier working were slim.
First, I split the training set into 3-4 categories:
- Images with no occurrences of the logo.
- A training set containing logos in every image.
- A test set (this test is used to validate the model against).
- More data with occurrences/no occurrences that aren’t used in the training or test set is needed.
A few considerations before starting training:
- Train every occurrence in a given image. Don’t leave any out. Otherwise, these samples will be added to the background class (which consists of anything else if only one label is trained).
- Make sure the model is evident in the image (e.g., resolution is good enough).
- The bounding box should be as tight as possible around the object but not clip off any feature or add too much background.
- Add any partially covered/corned/black-and-white or other coloured filtered labelled objects to the training set. Otherwise, they might not be recognised.
- Different types of logos need to be trained in their class.
Results
Results are classified and subdivided into 3 classes:
- True positives: an outcome where the model correctly predicts the positive class/trained model.
- False negative: an outcome where the model incorrectly predicts the negative class/background.
- False positive: an outcome where the model incorrectly predicts the positive class/trained model.
The following metrics define how well the model behaves:
- Precision: measures the percentage of true positives in the data set.
- Recall: shows how many labels in the training set are recalled correctly.
- F1 score: describes the harmonic mean of the precision and recall of the classification model. A good model is between 0.8 and 0.9; an excellent model yields > 0.9. Aim for at least 0.85 to minimise false negatives/positives.
A detailed description can be found here: https://encord.com/blog/f1-score-in-machine learning
Attempt 1
This model consists of 1 label, 73 images in the training set, and 73 in the test set. The training and test sets are random selections of images containing the monster logo, and both image sets do not overlap.
| Label name | F1 score | #Test images | Precision | Recall | Assumed Threshold |
| monster | 0.5 | 73 | 0.617 | 0.420 | 0.083 |
- Training took 18.84 minutes.
- The F1 score is too low. We are aiming for at least 0.85 and more.
The recall rate is 42%, meaning it doesn’t recognise 68% of trained logos within the trained images. - To run the model and to see results, the confidence score has to be set to 5%. This introduces a lot of false negatives. The assumed threshold is < 1%.
- True positives: 46 images; False positives: 13 images; False negatives: 15 images
- The confidence levels in the images are very low:
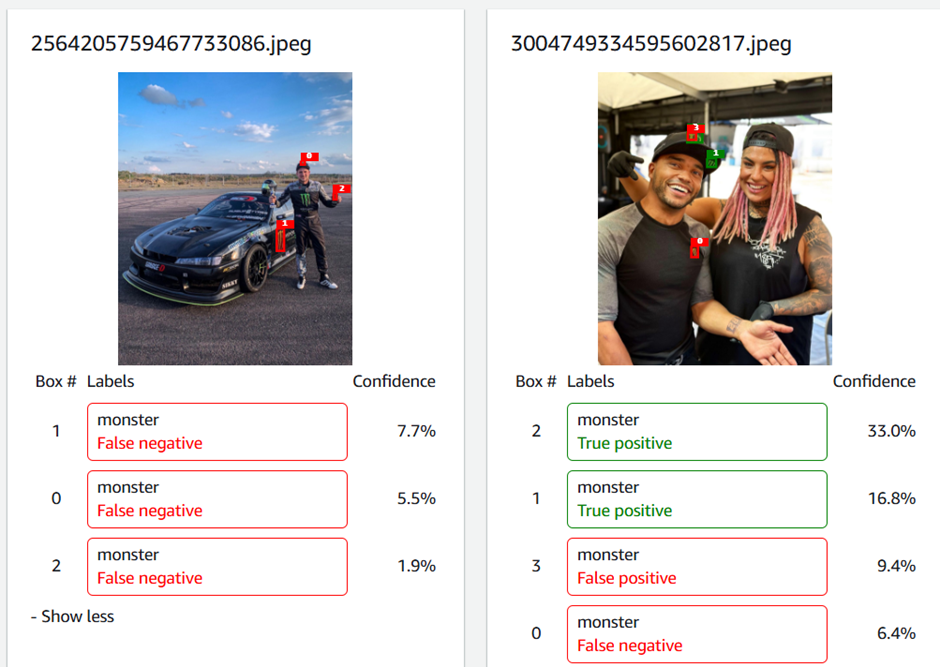
- Images where the logo points to the right-hand side are not detected and many logs are not recognised. It occasionally detects flags/buildings/fingers with a similar structure. In addition, there are overlapping bounding boxes for the same logo.
- Some examples from running against all images (confidence level 7):
 |  |
 |  |
Attempt 2
This model consists of 1 label, 104 images in the training set and 73 in the test set. Compared to the previous model, all occurrences are labelled in the training and test set.
| Label name | F1 score | #Test images | Precision | Recall | Assumed Threshold |
| monster | 0.867 | 74 | 0.920 | 0.820 | 0.525 |
- Training took 52.02 minutes.
- True positives: 71 images; False positives: 10 images; False negatives: 16 images
- The F1 score and precision have improved. Interestingly, the assumed threshold has decreased.
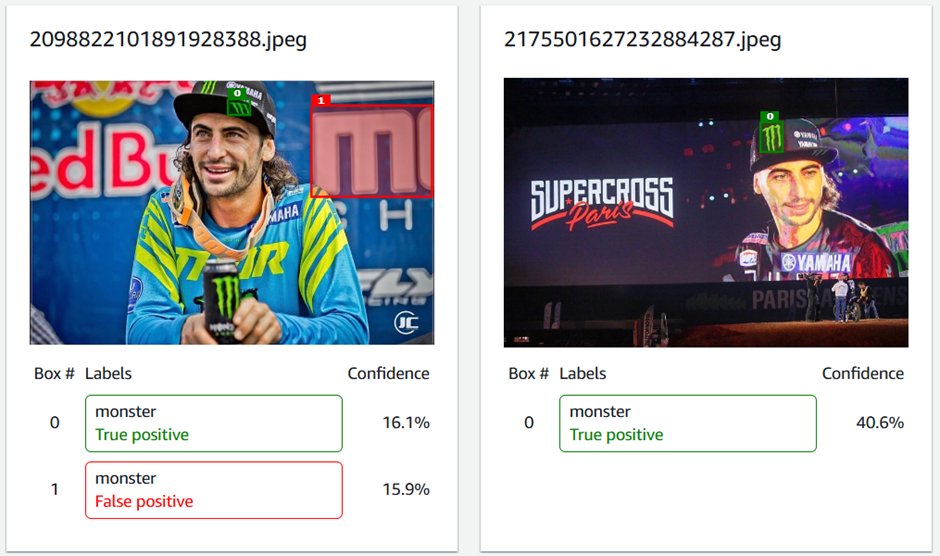
- The model details still contain a lot of false positives. Most of them look correct. This means that they have been forgotten during labelling (red bounding box):
Conclusion
- Every occurrence needs to be trained. Otherwise, it will be added to the negative class.
- Add an occurrence to the training data set if it is not recognised in an image. Do this for every non-detected occurrence.
- Because of its huge variations, this model requires a lot of images to be trained on.
- Some JPG image files failed to compute because they returned “request has invalid image format”. This was due to unsupported image size. Max image size 4096*4096. It is best to convert every image to PNG before storing it in S3. All limits can be seen here: https://docs.aws.amazon.com/rekognition/latest/customlabels-dg/limits.html
- When running the model, use a minimum confidence of 50. If possible, use a higher one, such as 65+.
This model was trained using the user interface provided by Amazon AWS. Creating a manifest file to programmatically define the bounding boxes for each image in the S3 bucket is possible.
The execution time varied depending on the image size; for example, 820*591 pixels was 317 ms, and 2725*4096 resulted in 959 ms. For all images, it ranged from 250 ms to 1.2 seconds.
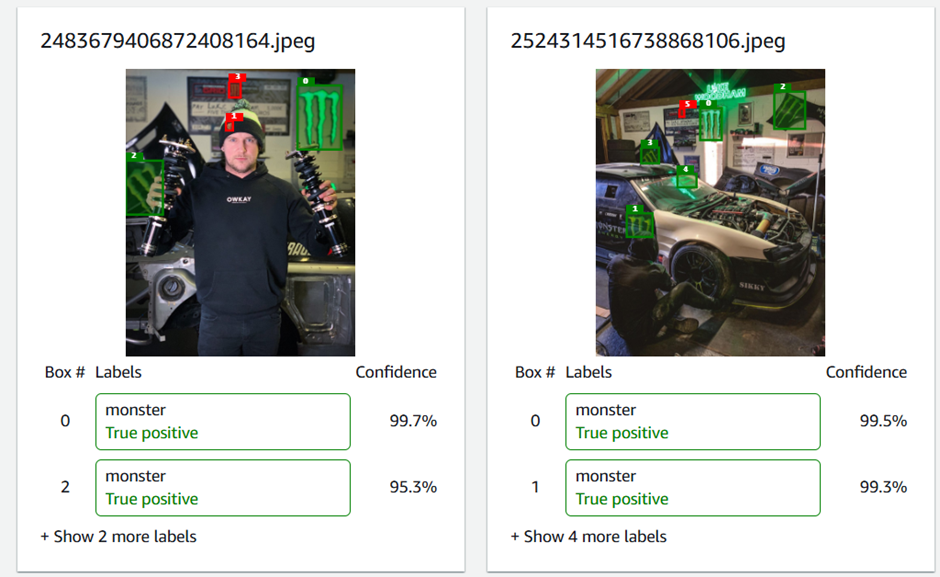
Below are some examples of the run classifier. Only 1 or 2 images were trained on different colour logos. Thus, what it can pick up is pretty impressive. The technical side of me wants to know how they extract their features 🙂
 |  |
 |  |
 |  |
 |  |
Fun fact: I now see the logo everywhere I go 😀 Unfortunately, a lot of these cans seem to end up on the streets.
 using WordPress and
using WordPress and
No responses yet